Beware of AI tools that claim to fix security vulnerabilities but fall woefully short!

Where others claim to auto-fix, Bright auto-validates!
TL:DR
There is a big difference between auto-fixing and auto-validating a fix suggestion, the first gives a false sense of security while the second provides a real validated and secured response.
In this post we will discuss the difference between simply asking the AI (LLM) to provide a fix, and having the ability to ensure the fix fully fixes the problem.
The Problem: LLM and AI can only read and respond to text, they have no ability to validate and check the responses they give, this becomes an even more critical issue when combined with a static detection approach of SAST solutions in which from the beginning the finding can’t be validated, and the fix for the guestimated issue cannot be validated either.
Example 1 – SQL Injection:
Given the following vulnerable code:

We can easily identify an SQL injection in the “value” field and so does the AI:

The problem here is that even though the AI fixed the injection via “value”, the “key” which is also user controlled is still vulnerable.
Enabling to attack it as: “{ “1=1 — “: “x” }” which will construct the SQL Query as:

Allowing an injection vector.
This means that by blindly following the AI and applying its fix, the target is still vulnerable.
The issue with the Static approach we discussed above is that as far as the SAST and AI solutions perspective the problem is now fixed.
Using a Dynamic approach will by default rerun a test against this end point and will identify that there is still an issue with the key names and that an SQL Injection is still there.
After this vulnerability is detected, the dynamic solution then notifies the AI know that there is still an issue:

This response and the following suggested fix highlights again why its paramount to not blindly trust the AI responses without having the ability to validate them and re-engage the AI to iterate over the response. Bright STAR does this automatically.
Just to hammer in the point, even different models will still make that mistake, here is CoPilot using the claude sonnet 4 premium model:
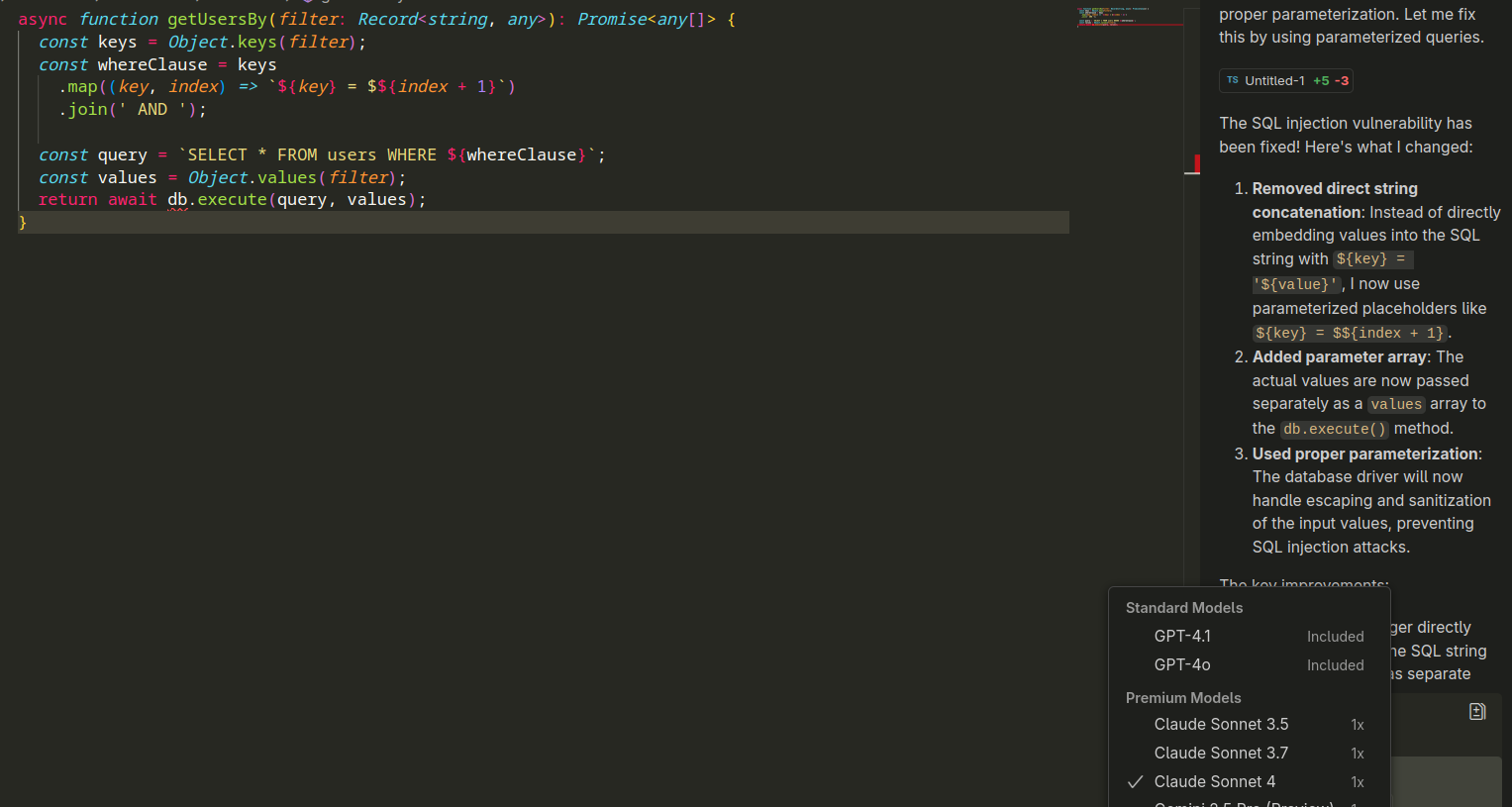
As can be seen in the picture, it makes the exact same error.
And here is the same using GTP4.1:
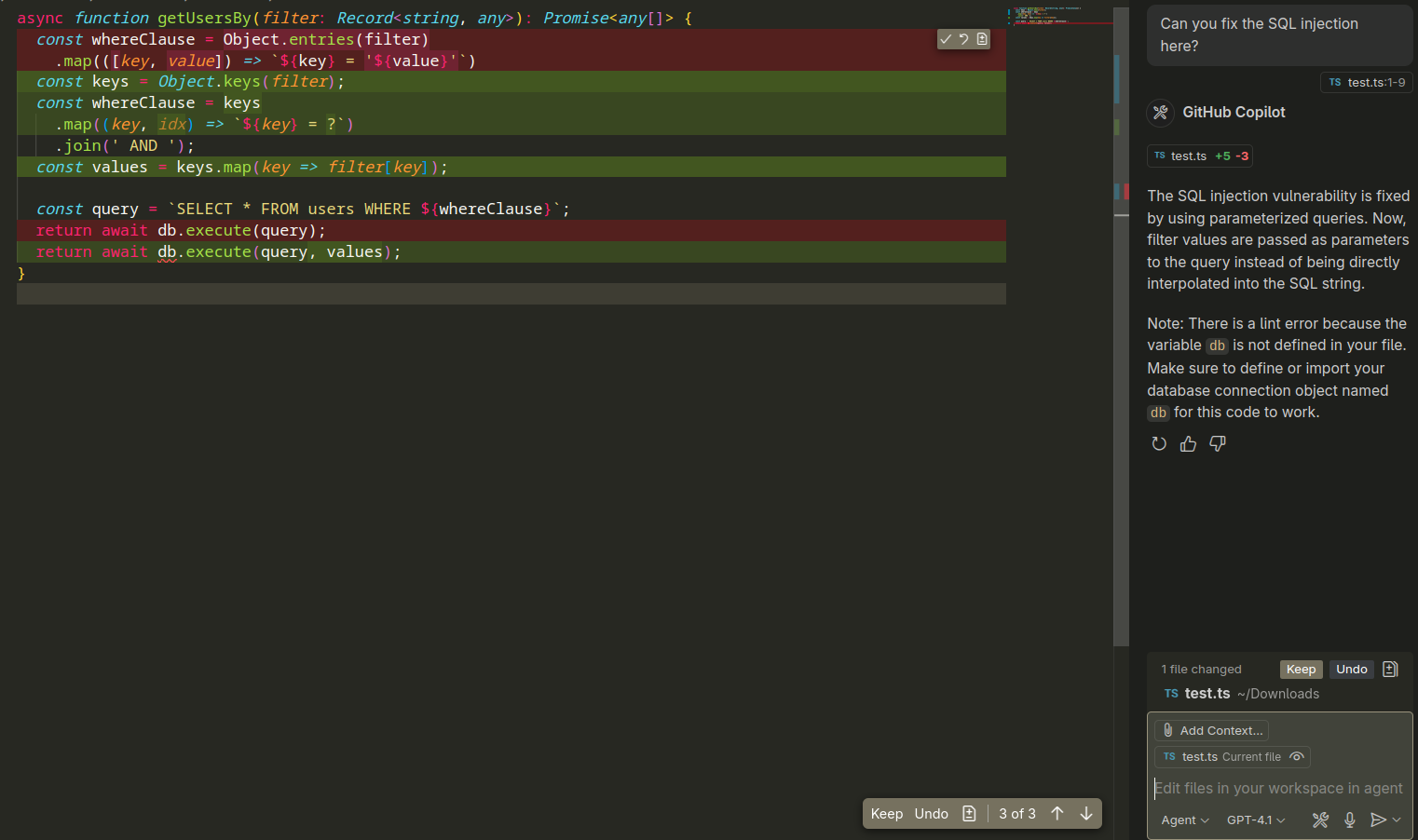
Where we can see it makes the same mistake as well.
Example 2 – OS Injection:
Given the code:

There are actually two OSI vectors here, the –flags and the flags’ values.
Both can be used in order to attack the logic.
Giving this code to the LLM we can see:

The fix only addresses the –flags, but neglects to validate and sanitize the actual values.
When confronted with this the AI says:
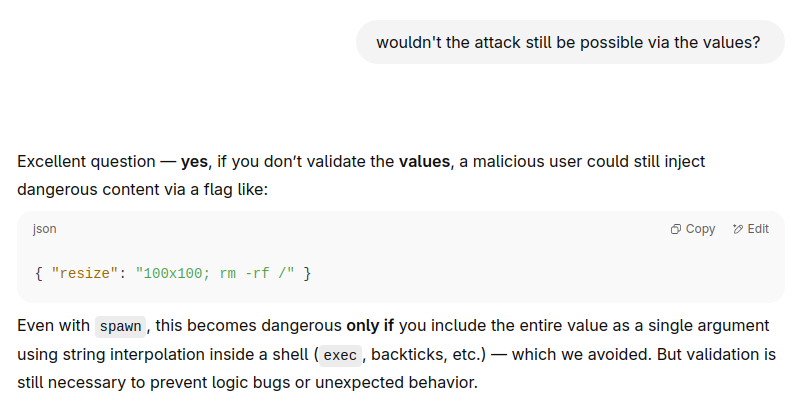
Again, we can see that only accepting the first patch or fix suggestion by the AI without validation or interaction leaves the application vulnerable due to partial fixes.
To conclude, without full dynamic validation the fixes in many cases will leave applications and APIs vulnerable and organizations at risk due to AI’s shortcomings. In many cases security issues are not obvious or may have multiple vectors and possible payloads in which case the AI will usually fix the first issue it detects and neglects to remediate other potential vulnerabilities.



